Overview
We will briefly describe the architecture of AutoLFADS, focusing on a high-level, theoretical overview over the basic organization and functionality of the various VMs created when beginning an AutoLFADS run. RADICaL follows exactly the same architecture as AutoLFADS. While this section describes the schema and theory behind the architecture of AutoLFADS, the steps to creating the basic architecture to begin an AutoLFADS or RADICaL run are described beginning in first-time setup.
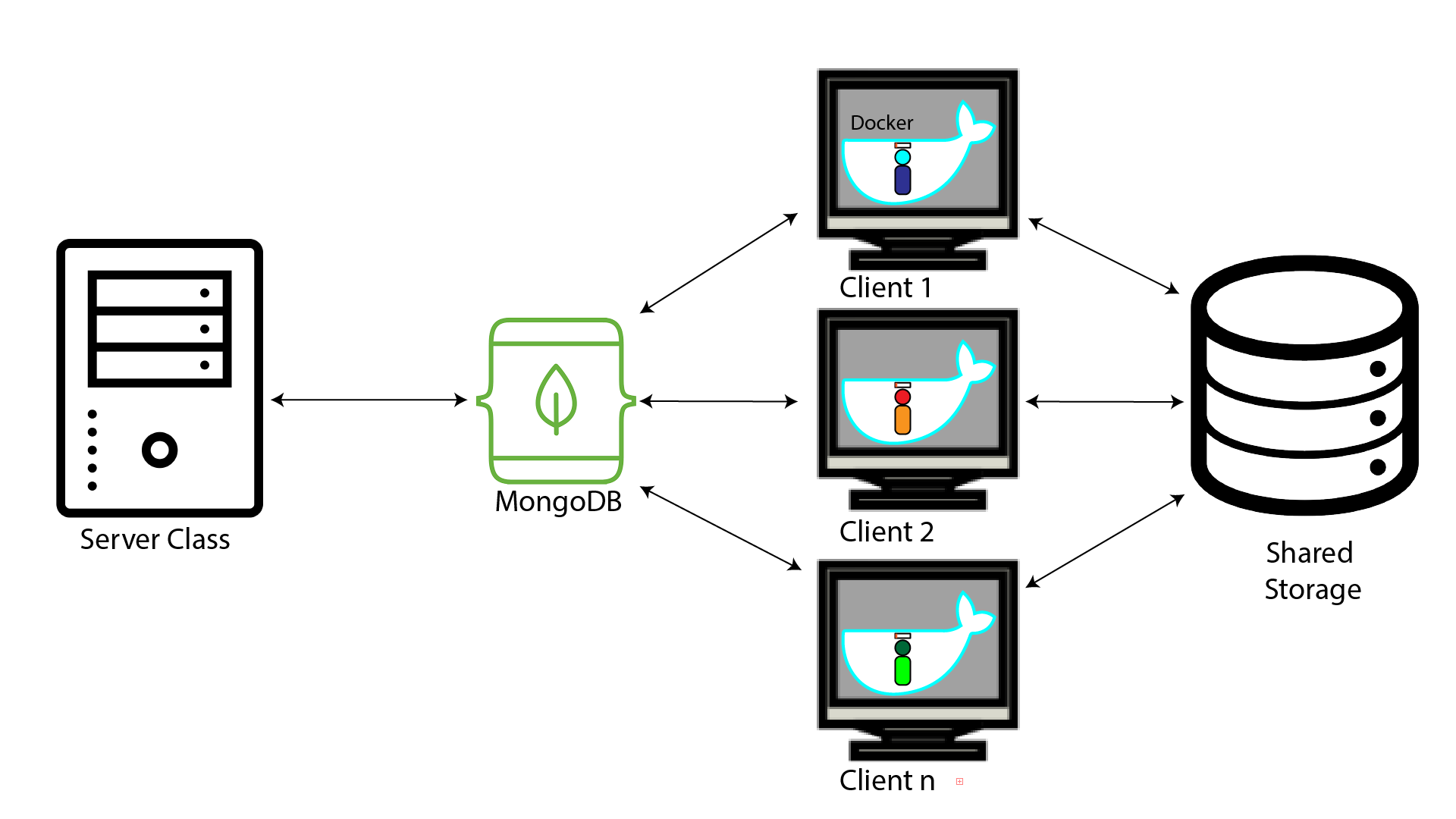
Server and Client
Server
The architecture of AutoLFADS is largely centered on using several virtual machines (VMs), which we can imagine as emulations of real computers. In any AutoLFADS run, we first create a single server machine, which we can imagine as essentially 'overseeing' an AutoLFADS run. It triggers all the workers to begin training, oversees exploit/explore methodology, and receives various data back from the worker population.
Client
The next group of virtual machines we create are called 'client machines.' We can conceptualize the client machines as the VMs which actually run LFADS, which send and recieve information from the server machine. Each client machine has its own GPU and can run 3 processes at a time, in which each process can be used to train a worker. Using more client machines allows us to more quickly model our data when we want large numbers of workers.
Docker, Shared Storage, and MongoDB
While the interplay between server and client forms the backbone of an AutoLFADS run, there are various components that facilitate this.
Docker
The workers are run by client machines, but a LFADS worker generally requires a complex software setup. To avoid manual user set-up, each client machine has a Docker image with the required LFADS environment. For each client machine, each worker is run inside a Docker container.
For more information on Docker, https://docs.docker.com/engine/docker-overview/ offers a more comprehensive overview.
Shared Storage
Shared storage contains the initial dataset AutoLFADS is analyzing, and throughout the run it stores the weights and HPs of each generation of worker.
MongoDB
We can imagine Mongo as facilitating the communication between server, clients, and shared storage. For instance, worker status is passed from the clients to server through Mongo.