Theory
This section details a general theoretical overview of AutoLFADS. We can generally think of AutoLFADS as a combination of LFADS with a hyperparameter tuning framework called population-based training, or PBT. We also include a general overview of RADICaL.
In order to understand AutoLFADS, we will first look at LFADS and PBT independently.
What is LFADS?
Populations of neurons show latent, low-dimensional structure that is not apparent from studying individual neurons, and this latent structure exhibits dynamics - a set of rules that determine how the system evolves. LFADS (Latent Factor Analysis of Dynamical Systems) is a deep learning tool which models these neural population dynamics.
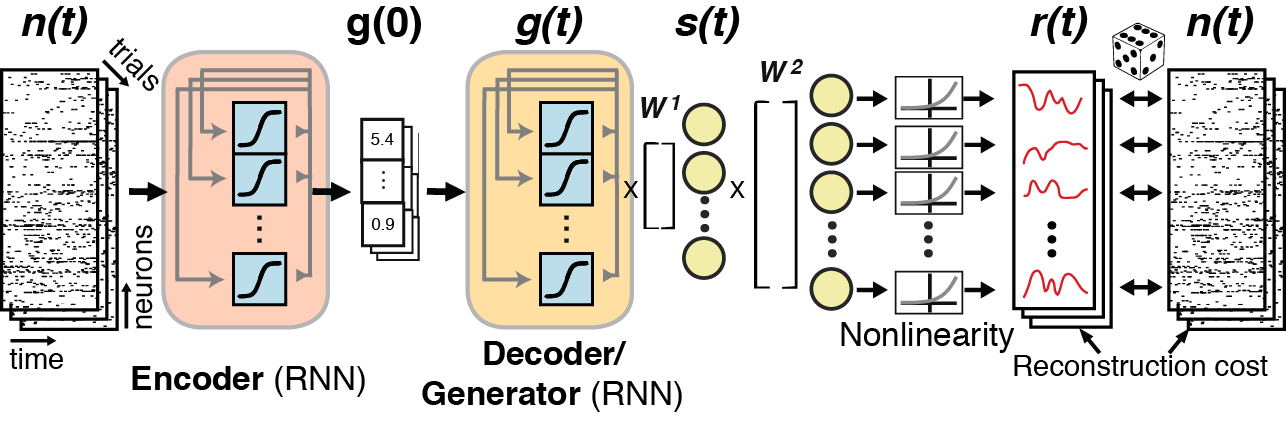
What is PBT?
The ability of LFADS to learn and train from data hinges on many values set prior to training, called hyperparameters (HPs). We can think of HPs as essentially the 'settings' of LFADS --- with improper settings, LFADS can train slowly or incompletely. However, it is difficult to know what the "correct" settings are, as the ideal HPs differs from dataset to dataset! In this way, LFADS with unoptimized hyperparameters will sometimes struggle to fit correctly to data.
PBT is a framework that allows optimization of hyperparameters. Thus, LFADS run with PBT, or what we deem AutoLFADS, can arrive at HPs that are far more optimized and can lead to far better performance than LFADS by itself.
How does PBT work?
PBT optimizes HPs during training through what is called 'evolutionary optimization,' a process modeled after evolutionary strategies. First, instead of training a single deep-learning model (for instance, LFADS) to completion, PBT generates an entire population of models, where each member of the population is an individual deep-learning model with randomly initialized unique HPs and weights. For convenience, an individual deep learning model with its own HPs and weights is deemed a 'worker.' With PBT, the entire population of workers is trained in parallel.
During training, weaker performing workers (models with suboptimal HPs and thus suboptimal weights) copy the HPs and weights of better performing workers, in code called exploit.
After exploiting, the values of the copied HPs are slightly changed as a way to search for more optimal HPs, in code called explore.
In this way, instead of workers with poorly optimized HPs floundering for an entire run, they instead steal the weights and HPs of the best performing worker and then search from there for even better optimized HPs. Thus, by the end of all the workers training, we end up with a strong performing best worker which has highly optimized HPs.
What is AutoLFADS?
AutoLFADS is the training of LFADS with a PBT framework for HP optimization. While LFADS will struggle in being applied to less-structured behaviors or brain areas not primarily governed by intrinsic dynamics, AutoLFADS with its HP optimization can achieve good performance in these diverse datasets.
Extension of AutoLFADS for modeling EMG activity
AutoLFADS was recently adapted for application to multi-muscle intramuscular EMG recordings. The observation model of the AutoLFADS model was modified to better match the statistics of EMG. Additionally, we introduced a novel data augmentation strategy to mitigate overfitting to high-magnitude artifacts sometimes present in EMG recordings.
What is RADICaL?
RADICaL is an extension of AutoLFADS for application to 2-photon (2p) calcium imaging data. It incorporates two major innovations over AutoLFADS. First, RADICaL's observation model was modified to better account for the statistics of deconvolved calcium events. Second, RADICaL integrated a novel neural network training strategy, selective backpropagation through time (SBTT), that exploits the staggered timing of 2p sampling of neuronal populations to recover network dynamics with high temporal precision.